The Illusion of Thinking and Agentic AIs
- Alex Bordei

- Jun 19, 2025
- 3 min read
Updated: Jun 20, 2025

I recently read a preprint paper¹ by Apple that sparked a bit of controversy. It claims that Large Reasoning Models (like DeepSeek) break down (more like catastrophic total collapse) after a certain limit of complexity. The accuracy collapse is stark in this data:
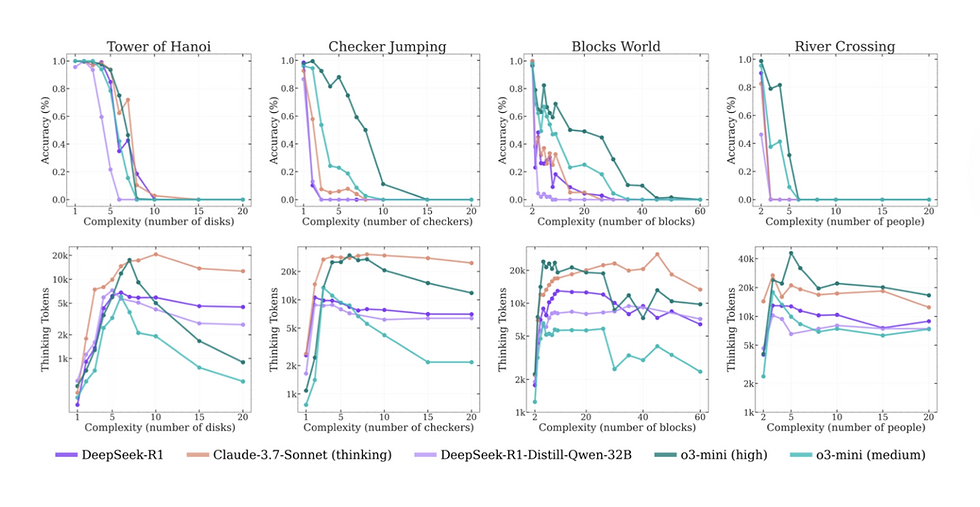
It got me worried as we are relying on the reasoning capability of the AI to help our clients perform network troubleshooting which is arguably similar in complexity to many of the artificial problems like the Tower of Hanoi used to evaluate the reasoning capabilities of the models.
In fact, the whole industry is working on Agentic AIs, and it is assumed that they will be at least as capable as humans at performing some of these tasks but if their reasoning is in fact limited and even totally collapses at some point it means you need to have significant safeguards in place (human-in-the-loop or other mechanisms) that will limit their applicability and performance at least for now.
The point where it collapses is also interesting. It is basically at the same level as humans. We too have a limit after around 5 disks in the Tower of Hanoi problem. 6 and 7 disks are extremely challenging for the average person (see foundational work on problem-solving by Simon, or studies on executive function using the Tower of Hanoi). Note however that the nature of the collapse is different (silent failure vs long time to solve, non-optimal moves etc.).
But there is a counter preprint paper² that looked closer at how the tests were conducted and concluded that the tests did not account for the token limitations of the models (the model needed to output more than x tokens and was not allowed to- counting as a failure) or that some of the river crossing problems were in fact unsolvable. Pfew.
Are we out of the woods? Can we trust the models with our complex network troubleshooting problems? I think the tests do show that there are limits, but not inherent to the technology per se. What this shows, and what the counter paper highlights, is how easy it is to confuse a model limitation with your own limitation.
I experienced this during the early days of the development of ELI. I was very much focused on parsing the outputs and the inputs to account for all situations, and one day I accidentally let raw, unfiltered data into the model, and I realized it was performing much better than all my complex ‘preparation’ code. By not trusting its capabilities, I was making it worse.
Regardless of the reasons, the models do collapse and do so without warning. Figuring out when a model collapses (for example, due to unreasonable constraints) and telling the user that it did will in fact, be an important challenge for many Agentic AI builders. The AI itself will most likely not realize that it failed.
As an industry, we have some work ahead of us. All agentic AI systems will need at the very least: - Validation Logic: have some external, good-old-fashioned hard-coded guardrails to validate the action.
- Self-Correction/Reflection: Have the AI check itself - Confidence Scores/Uncertainty Estimation: This is an active area of research. Right now, the models can’t tell you I’m 80% confident.
- Error Handling and User Feedback - Monitoring and Observability.
Ultimately, building trustworthy and robust agentic AI systems isn't just about raw model power, but about the intelligent design of the surrounding architecture.
[1] Shojaee, P., Mirzadeh, I., Alizadeh, K., Horton, M., Bengio, S., & Farajtabar, M. (2025). The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity. arXiv preprint arXiv:2506.06941. Link to arXiv.
[2] Opus, C., & Lawsen, A. (2025). The Illusion of the Illusion of Thinking: A Comment on Shojaee et al. (2025). arXiv preprint arXiv:2506.09250. Link to arXiv


